Importing flat files with inconsistent formatting is a classic problem for ETL (Extract Transform and Load) scenarios. You need to design a process to consume data from comma delimited flat files and as soon as you build the process to read in files of a particular “agreed upon” layout and column order you inevitably encounter a file or two that breaks with the “agreed upon” layout by reordering one or more columns or entirely missing columns of data. It seems you need a process to read the file and parse it before you read the data from the file and attempt to import it. Although this nut has been cracked before, I’d like to add another rather adaptive approach to the problem using T-SQL and SSIS.
I had a scenario recently where I needed to build a flat file data ETL process for a client. Unfortunately, the client isn’t the source of record for the data and had very little ability to dictate to the suppliers of the data any of the formatting or layouts of the file. The only thing that was somewhat consistent between the flat files were the data contents and data subject areas data types. Neither the order of the columns nor whether the same columns would be present in all the flat files could be relied upon. In the past this client’s personnel had spent a fairly significant amount of man hours importing these flat files into MS Excel and manipulating them by hand in order to produce a consistent layout that could then be subjected to an ETL process. So, I set out to build a new ETL process for them that would not care for the most part about the flat file layout inconsistencies and simply pull the file’s data contents into a database to be processed.
In order to accomplish this as the opening paragraph implies I had to build a process to import each file’s data contents as raw text records and then attempt to parse it once inside the database. To be fair I didn’t build the process from scratch myself. I Googled around a bit and found third party paid solutions, as well as technical articles and examples from others who were solving similar problems, but didn’t quite fit my immediate scenario. In order to give credit where credit is due, I got the most help from a TechNet article by Visakh16 and Andy ONeil dated January 24, 2015.1 As a matter of fact, my solution ended up being an adaptation of their code from this article.
Step 1
In order to attempt to parse the data contents of each csv flat file the file needed to be imported into a table in a raw unaltered format where each row in the flat file is loaded as a record or row in a single column table. This is accomplished with a standard Flat File connection manager inside the SSIS package with a few non-standard tweaks that may seem counterintuitive at first. Tweak 1) Uncheck the “Column names in the first data row” checkbox. Tweak 2) Make sure that the “Header rows to skip” is set to 0. Tweak 3) Set the “Header row delimiter” to {CR}{LF}.
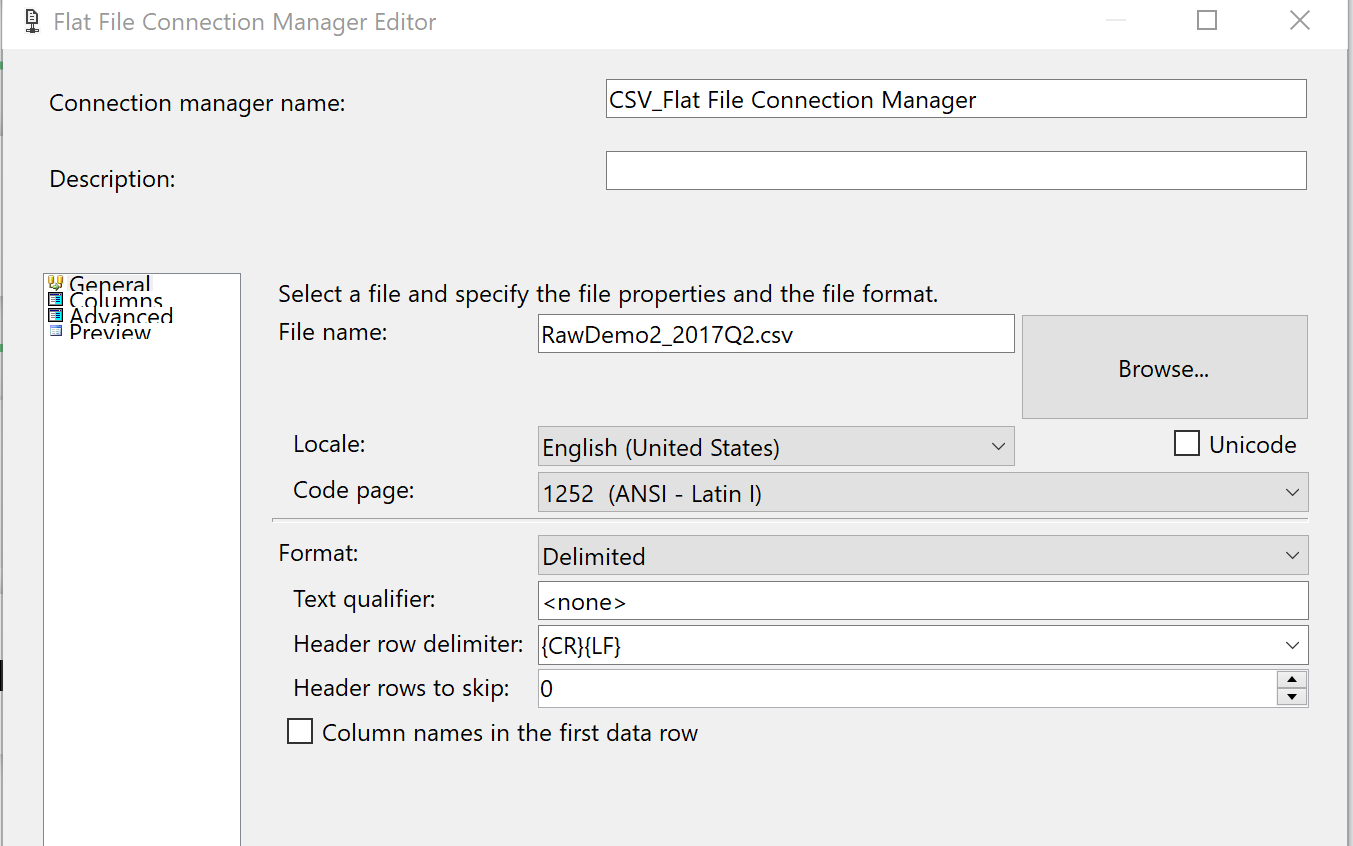
This should result in the data contents of the file being mapped into one very wide column.
Step 2
We need to build a table to accept the raw unparsed data from our new flat file import. This table needs only one column, but the column needs to be wide enough to accept whatever may come its way and a datatype that is very forgiving in the way of data contents. To solve these requirements I built the table with a NVARCHAR(MAX) datatype as NVARCHARs can accept Unicode characters and is therefore much more forgiving than VARCHARs and a width of (MAX) in order to accept insanely wide data strings as it must accept entire rows of unparsed data. You may call your table whatever you like, but I like descriptive names that convey the object’s purpose in life. In that vein see my table creation script below:
CREATE TABLE [dbo].[StagingTableVaryingColCSV](
[record] [nvarchar](max) NOT NULL
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
Before proceeding to step 3 let’s take a look at what the contents of one of our files looks like loaded into this table.
As you can see below from our SSIS Data Flow Task, that is importing our unparsed flat file, we should expect to see 883 new “records” in our StagingTableVaryingColCSV table.
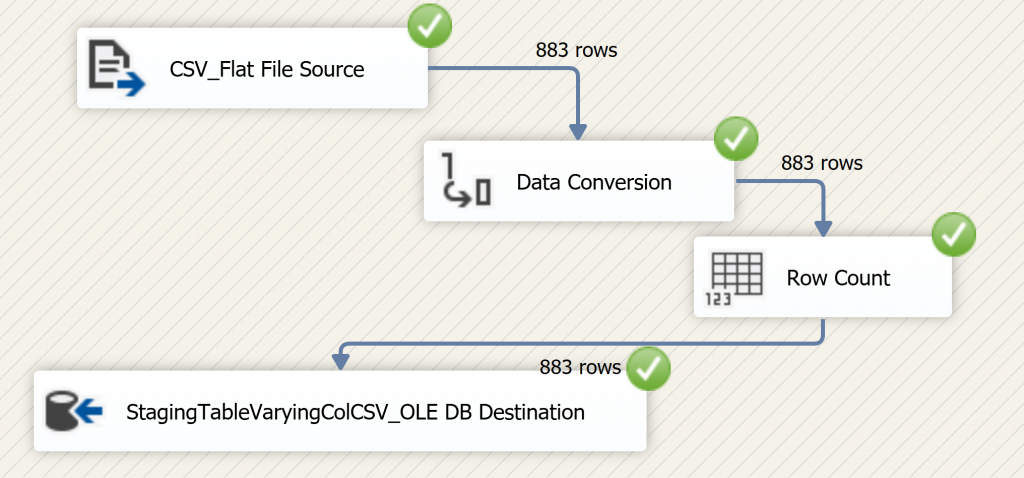
As we can see below that’s exactly what we have.

Do you notice anything peculiar about the first record in our table? That’s right; it contains our header row “data” as part of the table contents. This is desired; as we will soon be using it to dynamically map the contents of this table to its intended target table as part of the parsing process.
Step 3
Parsing the data. This is where the magic happens. Obviously, in order to use the data from our flat file we have to eventually read and parse it. Now that the data exists within a table inside the database we will accomplish this by using T-SQL. Our T-SQL approach uses two objects. The first is a user-defined function called udf_ParseValues whose job it is to take in each row and parse it to be returned as a dynamic “table” with columns based on the number of commas found in the input rows. See raw code below:
CREATE FUNCTION [dbo].[udf_ParseValues]
(@String varchar(8000), @Delimiter varchar(10) )
RETURNS @RESULTS TABLE (ID int identity(1,1), Val varchar(8000))
AS
BEGIN
DECLARE @Value varchar(100)
WHILE @String is not null
BEGIN
SELECT @Value=CASE WHEN PATINDEX('%'+@Delimiter+'%',@String) >0 THEN LEFT(@String,PATINDEX('%'+@Delimiter+'%',@String)-1) ELSE @String END
, @String=CASE WHEN PATINDEX('%'+@Delimiter+'%',@String) >0 THEN SUBSTRING(@String,PATINDEX('%'+@Delimiter+'%',@String)+LEN(@Delimiter),LEN(@String)) ELSE NULL END
INSERT INTO @RESULTS (Val)
SELECT @Value
END
RETURN
END
GO
The second piece of T-SQL is a stored procedure that has three functions. It will call our udf and accept the new columns of dynamic data returned from it and use a pivot query to produce columns based on the number of columns found in the file. It will then both filter out the header row record from the results and use it to build a dynamic SQL insert statement. Finally the stored procedure accepts two input parameters: a) InputFileType which is meant to be a friendly name for the data contents of the file such as “Marketing” data and for any special purpose logic that may be necessary for individual InputFileTypes and b) DestinationTable name which is used to complete the dynamically generated SQL Insert Statement along with the dynamically generated Select statement. In this way, a single stored procedure can be used to dynamically map any flat file data contents to any destination table within the database based on the combination of the destination table parameter and the contents of the file itself. See raw code below:
CREATE PROC [dbo].[usp_ParseVaryingColumnFileData]
(
@DestinationTable VARCHAR(36)
,@InputFileType VARCHAR(36)
)
AS
BEGIN
DECLARE @MaxRows int;
DECLARE @DestinationTableColsList VARCHAR(2000);
DECLARE @DestinationTableColsListRaw VARCHAR(2000);
DECLARE @InsertDynSQL VARCHAR(4000);
--SELECT @MaxRows = MAX(LEN([record]) - LEN(REPLACE([record],',','')))
--FROM dbo.StagingTableVaryingColCSV
DECLARE @ColList varchar(8000);
--Remove double quotes before attempting import
UPDATE dbo.StagingTableVaryingColCSV
SET record = replace(record, '"','');
SELECT @DestinationTableColsListRaw = (SELECT TOP 1 record
FROM dbo.StagingTableVaryingColCSV WITH (NOLOCK));
SELECT @MaxRows = (LEN(@DestinationTableColsListRaw) - LEN(REPLACE(@DestinationTableColsListRaw,',','')) + 1);
--Marketing data: Fix destination table column names before attempting dynamic mapping for insert statement
SELECT @DestinationTableColsList = (SELECT TOP 1
lower(replace(replace(replace(replace(@DestinationTableColsListRaw, '(Y or N)', ''),
'LTC_Insurance (Y or N)', 'ltc_insurance'), 'US_Veteran (Y or N)', 'us_veteran'),
'VA_Benefits (Y or N)', 'va_benefits'))
FROM dbo.StagingTableVaryingColCSV WITH (NOLOCK)
WHERE Upper(@InputFileType) = 'MARKETING'
);
SELECT @DestinationTableColsList = @DestinationTableColsListRaw
WHERE @DestinationTableColsList IS NULL;
SELECT @DestinationTableColsList = replace(@DestinationTableColsList, ' ', '');
SET @InsertDynSQL = 'Insert Into ' + @DestinationTable + '(' + @DestinationTableColsList + ')';
SELECT @InsertDynSQL = replace(replace(replace(@InsertDynSQL,'(', '(['),')','])'), ',','],[');
;With Number(N)
AS
(
SELECT 1
UNION ALL
SELECT 1
UNION ALL
SELECT 1
),Num_Matrix(Seq)
AS
(
SELECT ROW_NUMBER() OVER(ORDER BY (SELECT 1))
FROM Number n1
CROSS JOIN Number n2
CROSS JOIN Number n3
CROSS JOIN Number n4
CROSS JOIN Number n5
)
SELECT @ColList = STUFF((SELECT ',[' + CAST(Seq AS varchar(10)) + ']'
FROM Num_Matrix WHERE Seq <=@MaxRows FOR XML PATH('')),1,1,'')
DECLARE @SQL varchar(max)= @InsertDynSQL + ' SELECT '+ @ColList + '
FROM
(
SELECT *
FROM dbo.StagingTableVaryingColCSV t
CROSS APPLY dbo.udf_ParseValues(t.[record],'','')f
)m
PIVOT(MAX(Val) FOR ID IN ('+ @ColList + '))P
WHERE P.record <> ''' + @DestinationTableColsListRaw + ''''
--SELECT @SQL
EXEC(@SQL);
--Optional so as to clear out the source table once parsed in order to make room for --the contents of the next file to be parsed.
TRUNCATE TABLE dbo.StagingTableVaryingColCSV;
END;
GO
Now we will call the stored procedure manually and show you an example of the resulting dynamically generated SQL Insert Statement.
Raw Code for Calling the stored procedure:
DECLARE @RC int
DECLARE @DestinationTable varchar(36)
DECLARE @InputFileType varchar(36)
-- TODO: Set parameter values here.
SET @DestinationTable = 'marketing_raw'
SET @InputFileType = 'Marketing'
EXECUTE @RC = [dbo].[usp_ParseVaryingColumnFileData_DemoVer]
@DestinationTable
,@InputFileType
GO
Results
INSERT INTO marketing_raw
([customer_num],
[participant_id],
[site],
[last_name],
[first_name],
[middle_initial],
[suffix],
[gender],
[birth_date],
[death_date],
[program_enrollment_date],
[program_disenrollment_date],
[site_enrollment_date],
[site_disenrollment_date],
[disenroll_reason_full],
[place_of_death],
[ssn],
[medicare_num],
[entitlement],
[medicaid_num],
[race],
[ethnicity],
[place_of_residence],
[participant_lives_with],
[address],
[city],
[state_code],
[zip_code],
[zip_4],
[county],
[ltc_insurance],
[us_veteran],
[va_benefits]
)
SELECT [1],
[2],
[3],
[4],
[5],
[6],
[7],
[8],
[9],
[10],
[11],
[12],
[13],
[14],
[15],
[16],
[17],
[18],
[19],
[20],
[21],
[22],
[23],
[24],
[25],
[26],
[27],
[28],
[29],
[30],
[31],
[32],
[33]
FROM
(
SELECT *
FROM dbo.StagingTableVaryingColCSV t
CROSS APPLY dbo.udf_ParseValues(t.[record], ',') f
) m PIVOT(MAX(Val) FOR ID IN([1],
[2],
[3],
[4],
[5],
[6],
[7],
[8],
[9],
[10],
[11],
[12],
[13],
[14],
[15],
[16],
[17],
[18],
[19],
[20],
[21],
[22],
[23],
[24],
[25],
[26],
[27],
[28],
[29],
[30],
[31],
[32],
[33])) P
WHERE P.record <> 'contract_num,participant_id,site,last_name,first_name,middle_initial,suffix,gender,birth_date,
death_date,program_enrollment_date,program_disenrollment_date,site_enrollment_date,site_disenrollment_date,disenroll_reason_full,place_of_death,ssn,
medicare_num,medicare_entitlement,medicaid_num,race,ethnicity,place_of_residence,participant_lives_with,address,city,state_code,zip_code,zip_4,county,
LTC_Insurance (Y or N),US_Veteran (Y or N),VA_Benefits (Y or N)';
Note: Because both the Insert statement and its corresponding Select statement are dynamically generated based on the parsing of the data contents from the file and the stored procedures’ input values the ordering of the columns and even whether a column is present in the file or not becomes mostly irrelevant. The parsing and the data mapping occurs dynamically and in one step making this approach very versatile.
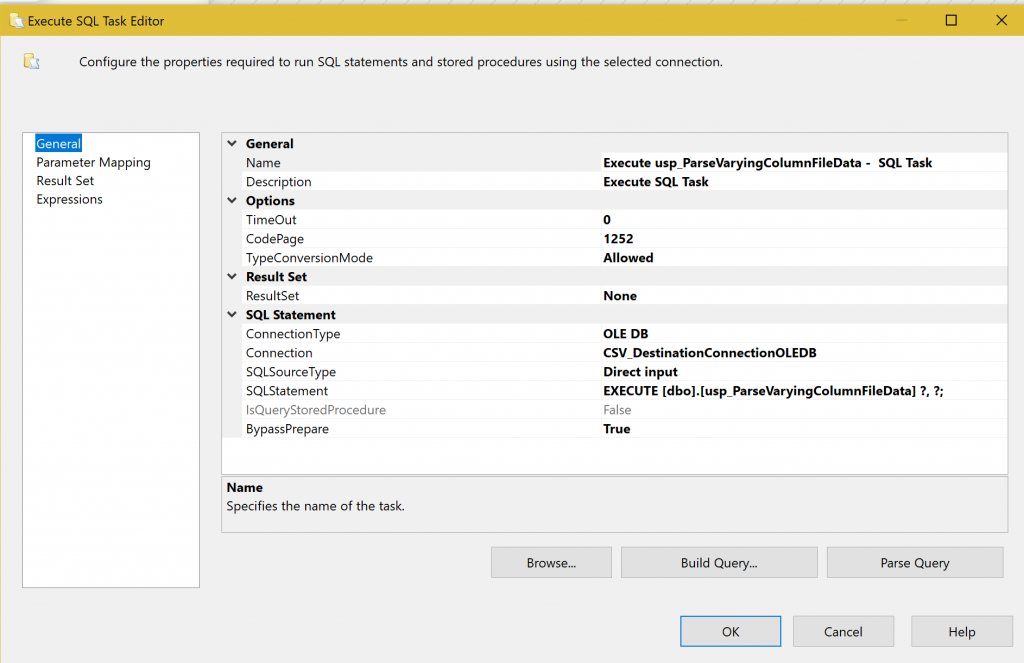
Now that step 3 code is complete and functional we have the simple task of calling it from within our SSIS package after “Data Flow Task” has loaded the unparsed data from the flat file. For this, we use a generic “Execute SQL Task” and point it to the “usp_ParseVaryingColumnFileData” stored procedure and wire up the stored procedure’s input parameters to our SSIS package pre-defined user variables.
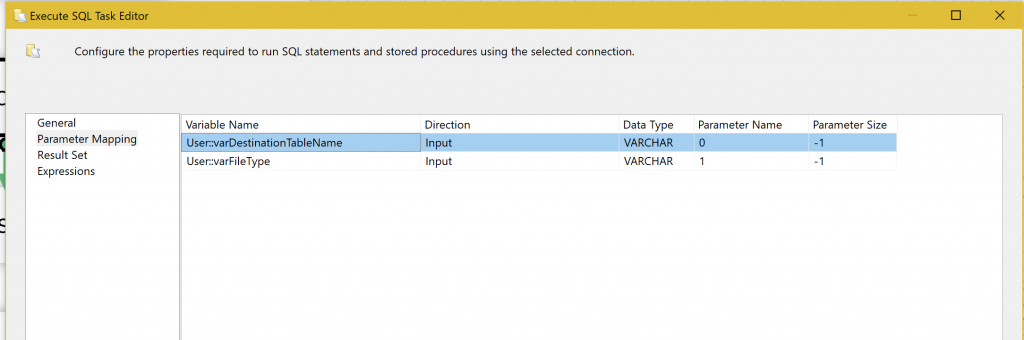
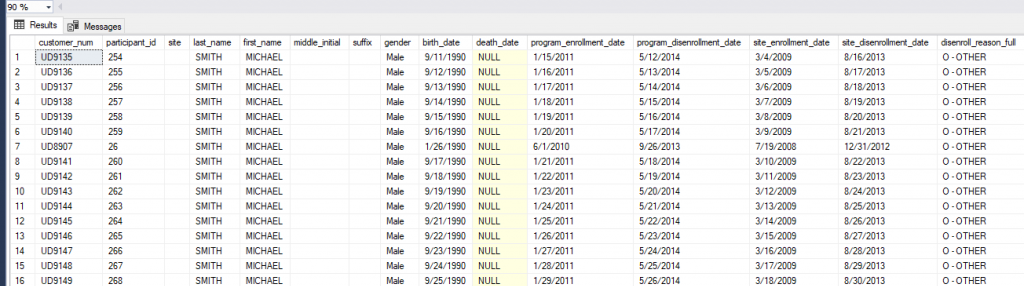
As you can see from our next and final screenshot our marketing_raw table now has data in the appropriate columns in spite of our inconsistent flat file layouts.
Now all that’s left is to wrap all of this in a SSIS “FOR EACH File – ENUMERATOR CONTAINER” so that we can loop through each of our non-standardized csv files and load them. For more information on that please refer to this link.
Hopefully you will find some useful tidbits in this article to solve a similar flat file conundrum that you may currently have or perhaps this can be a tool in your SSIS toolbox for flat file challenges you may experience in the future.
1 – https://social.technet.microsoft.com/wiki/contents/articles/29153.ssis-importing-flatfiles-with-varying-number-of-columns-across-rows.aspx
