As more organizations migrate to the cloud from legacy and traditional databases / warehouses, managers want to know the best route. How do we modernize our data quickly and effectively in a manner that offers a balance in ease of use and cost while maintaining the familiarity with data structures for end-users, analysts and developers?
Lucky for us, Matillion recently launched the Matillion Data Loader. Matillion is a cloud-based, drag-and-drop ELT application. Data Loader is their solution to streamlined (easy and low cost) data pipelines for cloud migration.
Matillion Data Loader will allow us to migrate an existing MySQL database and its structure to our Snowflake warehouse. This is called the “lift and shift” approach and though we may only need the E (extract) and L (load) of ELT for now, we want to use an application (or set of applications) that provide flexibility in case we want to leverage the cloud for our transformations in the future.
To show just how easy it is, we’ll walk through an example of configuring a pipeline. In our example, we will migrate data from an existing MySQL database ultimately landing our data in a Snowflake environment.
In order to build our pipeline, we’ll first need to sign up for an account.
After signing up and logging into the system you’ll see a mostly blank screen—with directions to add a pipeline.
In order to start leveraging a pipeline, you’ll need to configure source and destination data sources. In our case, this will be MySQL to Snowflake. We’re not limited to MySQL. Matillion Data Loader comes with a wide range of source databases / APIs. Destinations are currently available for Amazon Redshift, Google BigQuery and Snowflake cloud data warehouses.
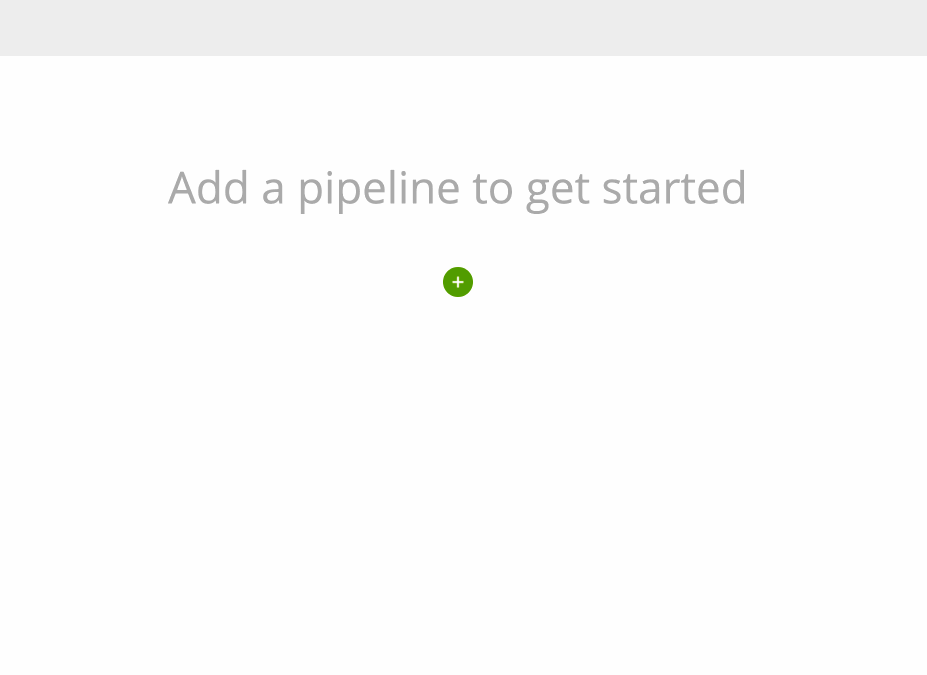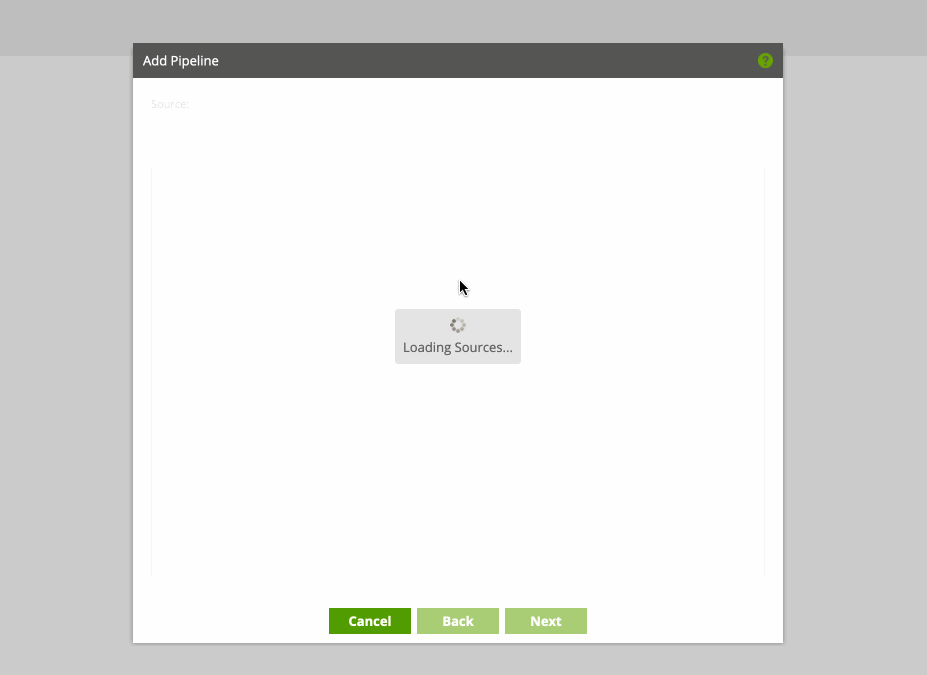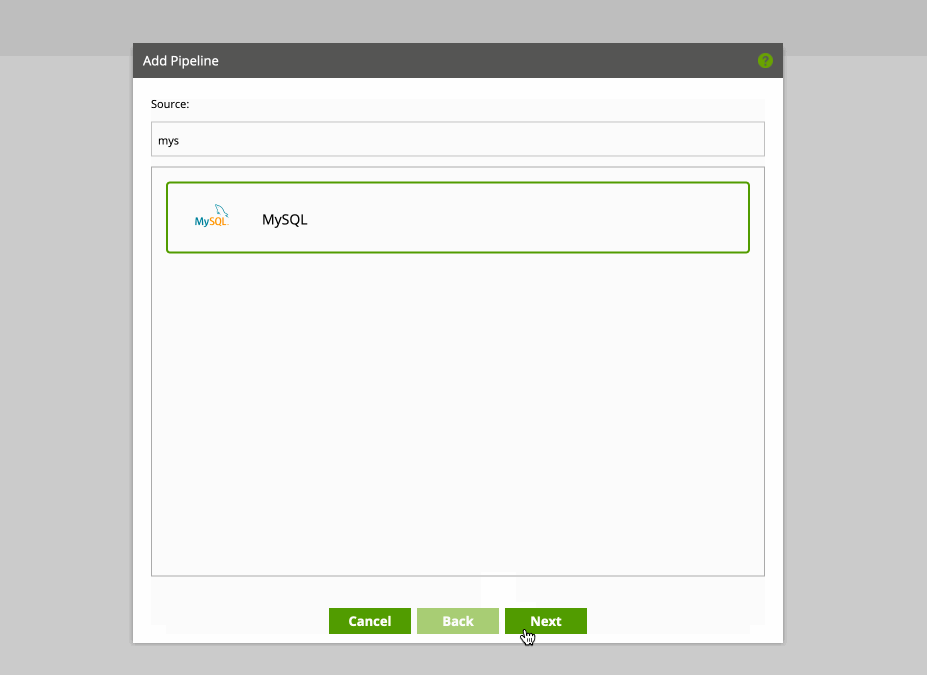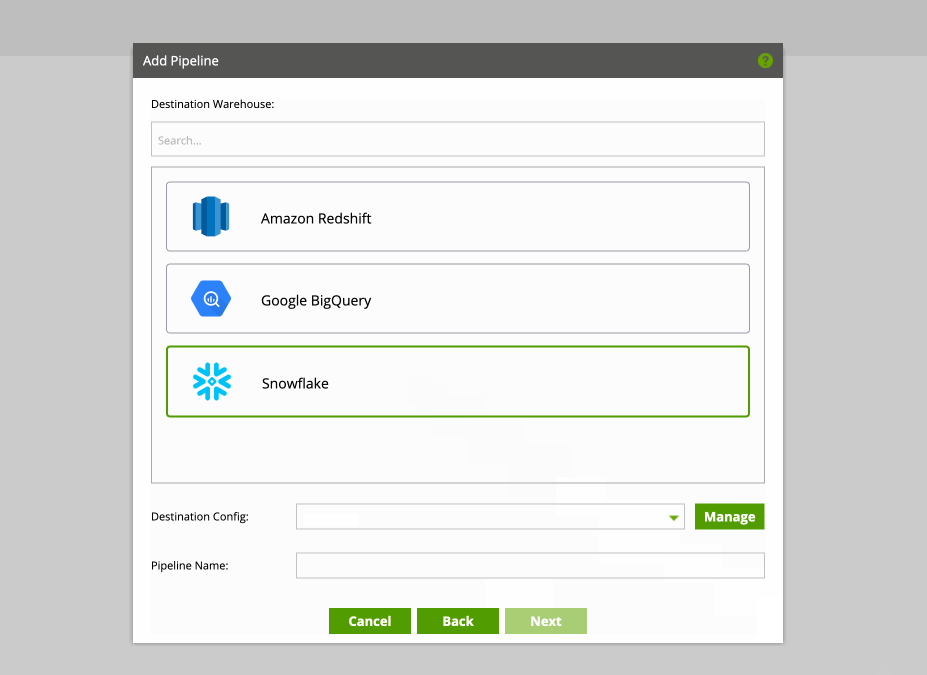
During configuration of the destination data source you’ll need the following information:
- Account: You can find this information via the url in your browser window while logged into Snowflake. Make sure to ONLY include information after https:// and before snowflakecomputing.com. For example, if my URL reads https://my-account.us-east-1.snowflakecomputing.com then I would simply put my-account.us-east-1 in this section.
- Username: If possible, I would suggest creating a new user for Matillion purposes as this makes it easier to track usage and compute credits.
- Password Type: Your organization may have security requirements to use private keys over a password—both are available options.
- Password:
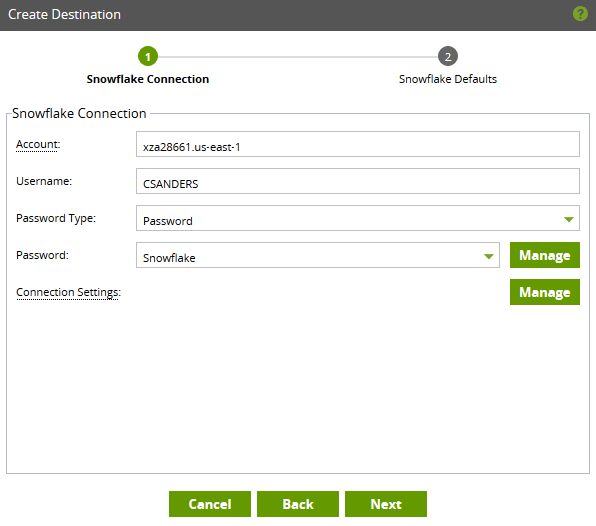
You will need to add a password via the Manage button, this will make adding future pipelines more straightforward (eliminating the need to enter your password each time the pipeline runs).
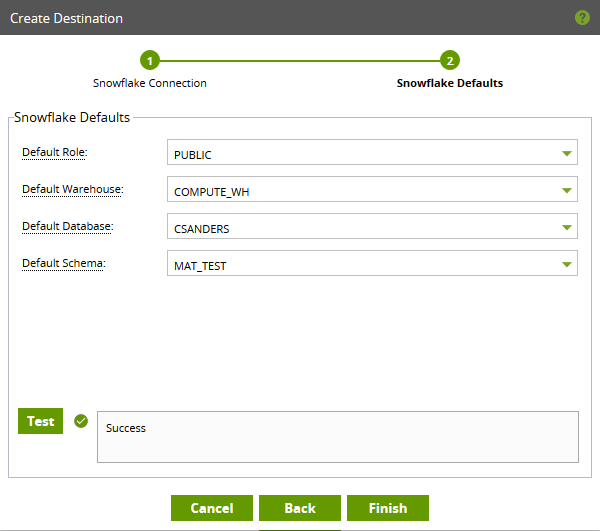
Next, you’ll need to identify the appropriate role, warehouse, database and schema. I recommend testing to ensure connectivity.
Congrats! You’ve now configured your destination—now we’ll need to move onto our source, which is a similar process.
When navigating through the source configuration, you’ll need the following information:
- JDBC Connection String / URL and database
- E.g. – jdbc:mysql://mysqlhoststring/database
- Username
- Password (add a new password via the Manage button)
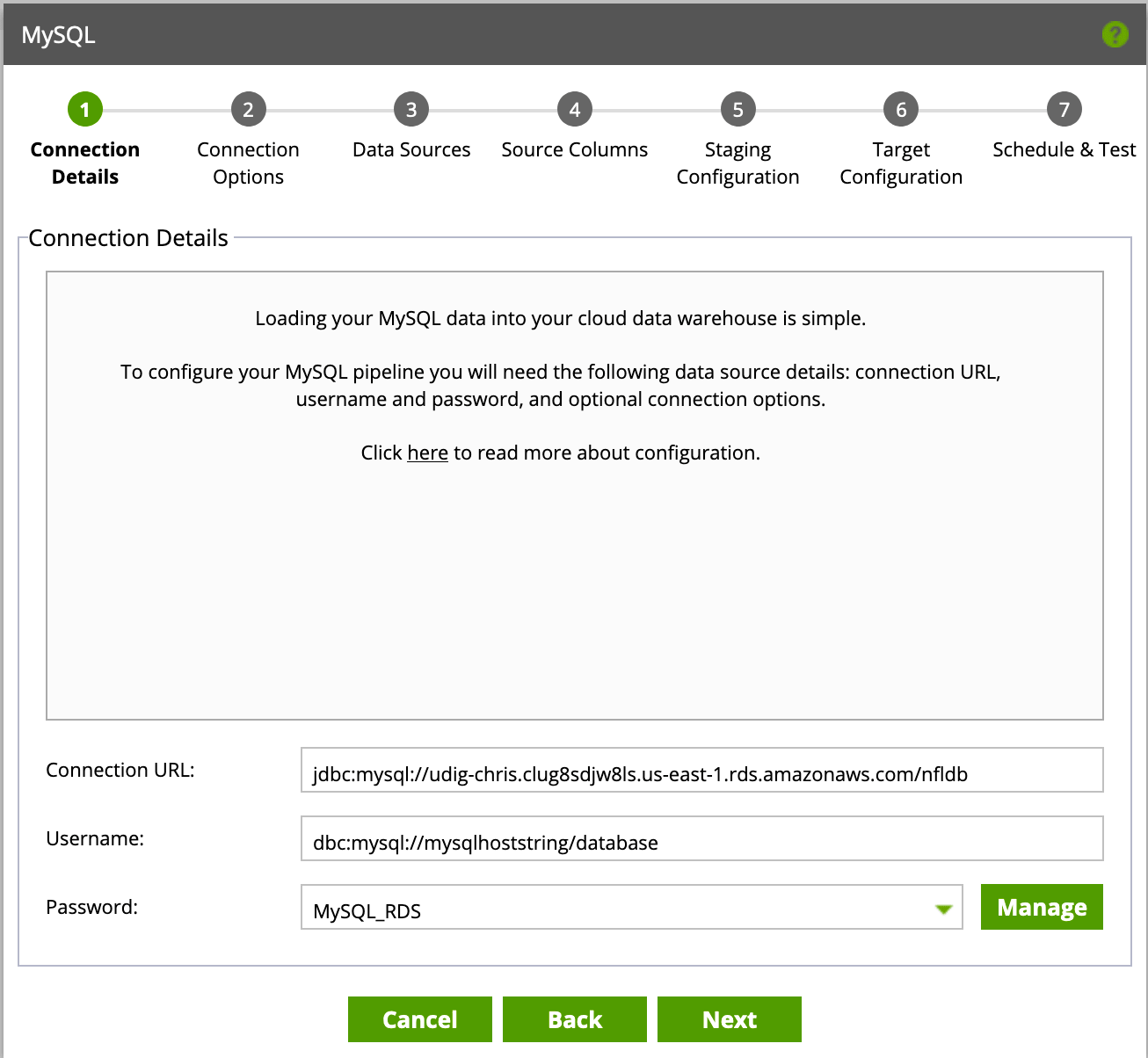
Click next until you see the following menu, which will allow you to decide which tables you’d like to load data from.
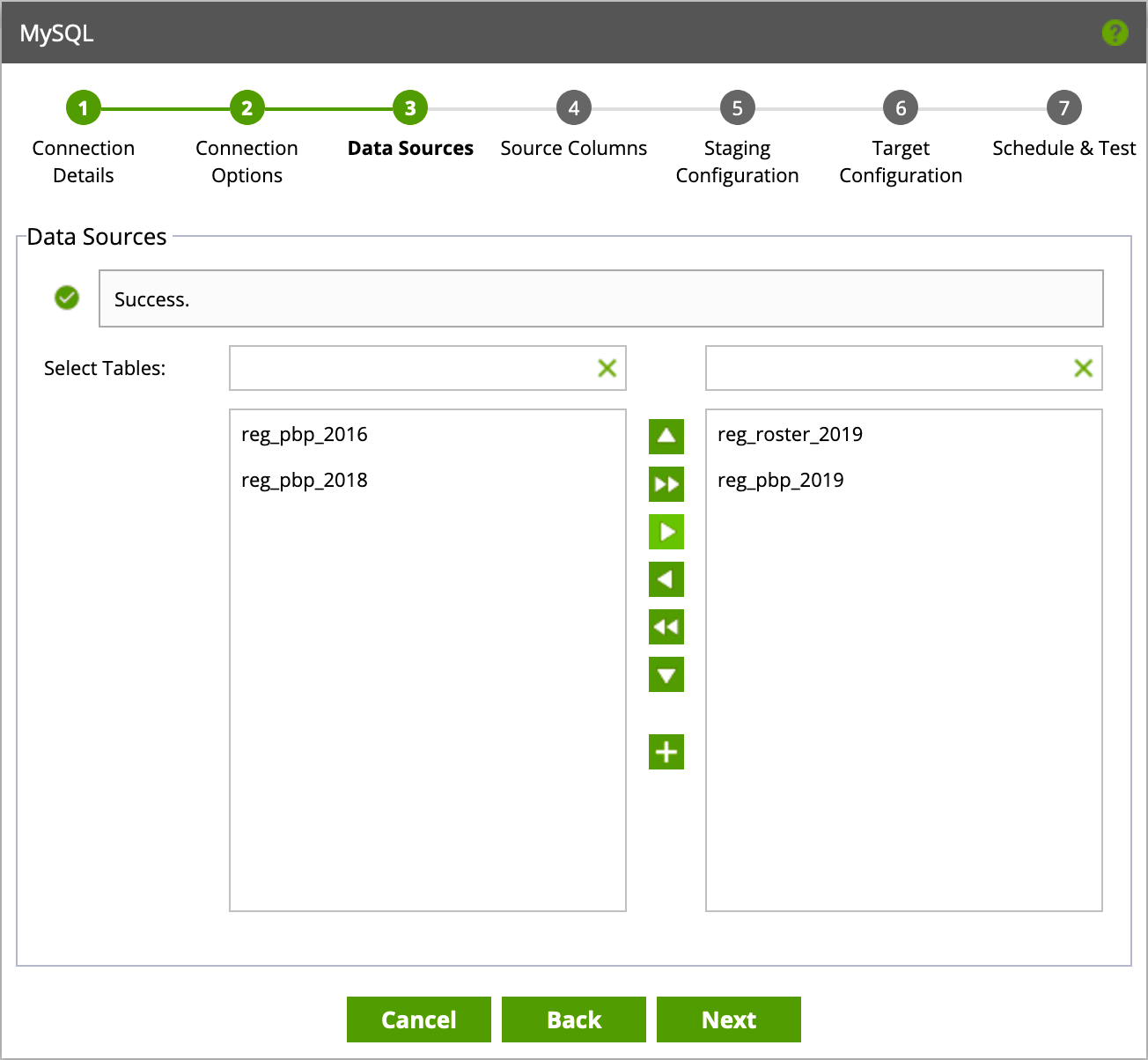
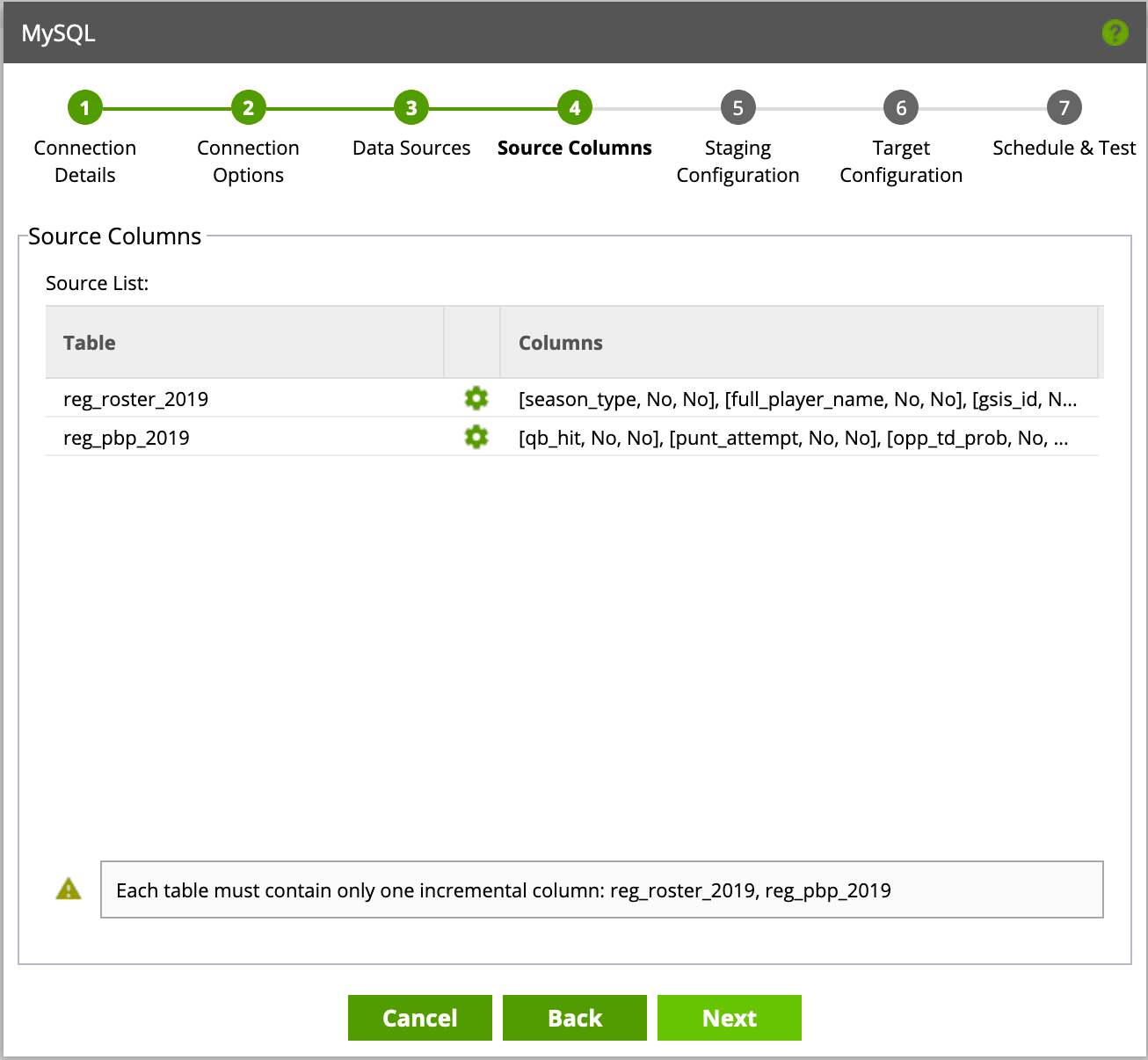
After selecting your tables, you will have the option of defining field types as well as any incremental columns to leverage as an incremental field. Each table is limited to a single incremental field. Incremental fields will allow for faster data loading, as only the newest rows will be migrated instead of full table refreshes.
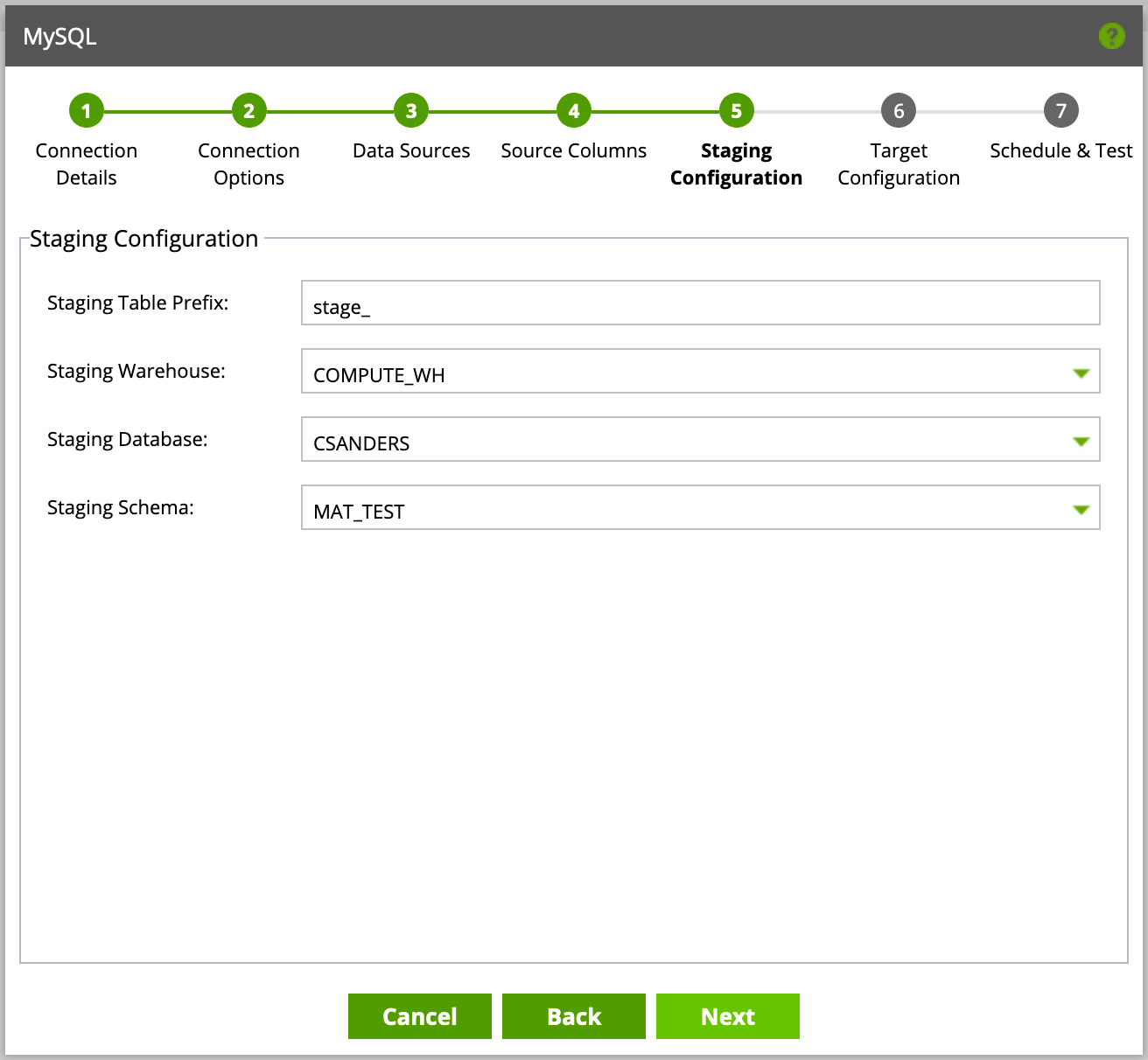
Click Next, and define the database, schema and warehouse (for compute purposes) you want your pipeline to use. You’ll need to do this twice—once for staging (where data will live temporarily as Matillion loads the data incrementally) and then again as your target (where data will ultimately land for analysis).
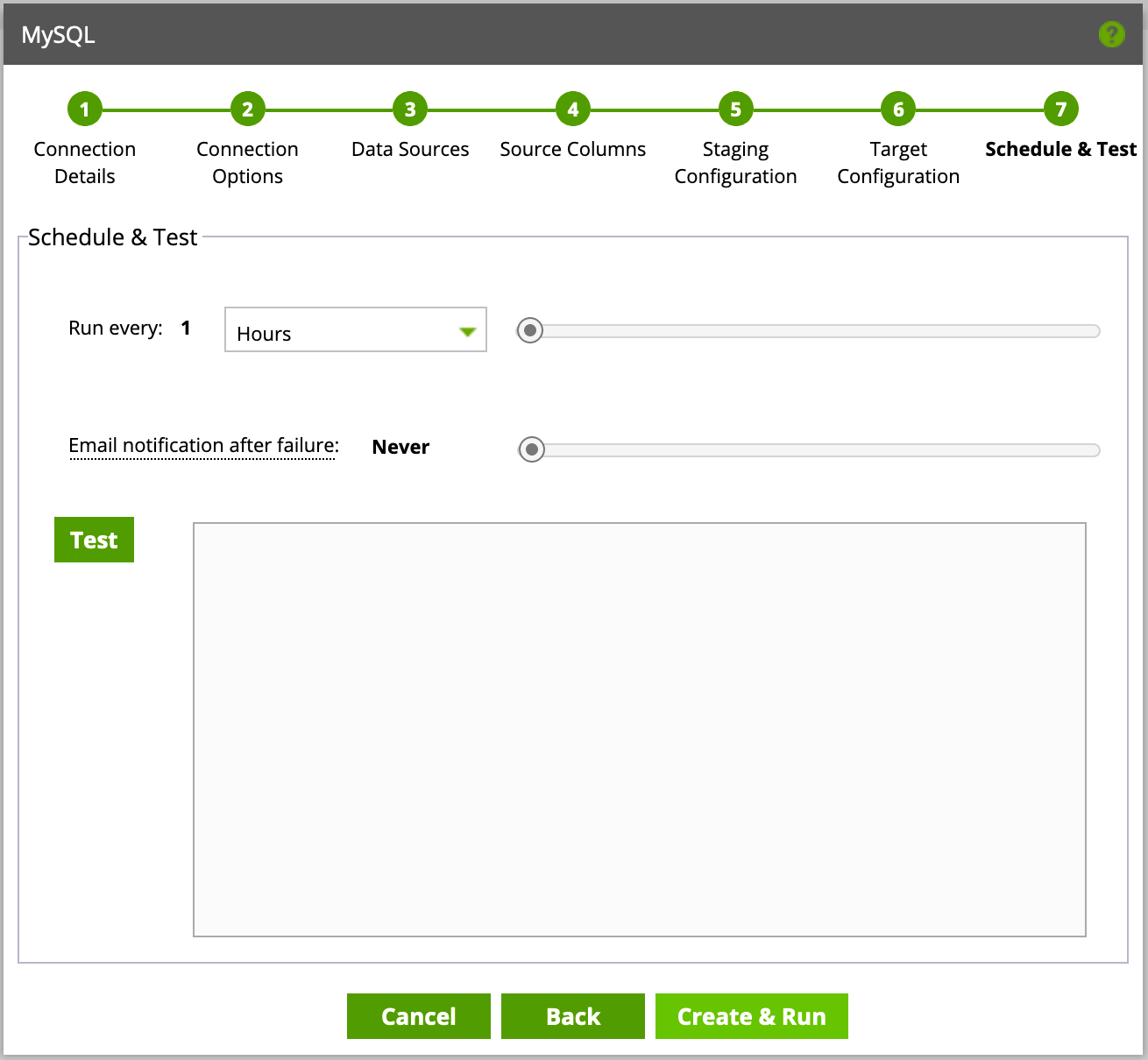
Finally, you’ll be presented with scheduling options—configure these as needed but note that each run will leverage compute (and will consume Snowflake usage credits). Additionally, you can choose to receive failure notices should a pipeline fail.
Congratulations! You’ve now configured your first pipeline! The tool presents you with a view that displays historical run information as well as the frequency of run and the number of rows migrated. Should you ever need to turn off the pipeline or make a change in frequency, you can do so using the menu in the top left.
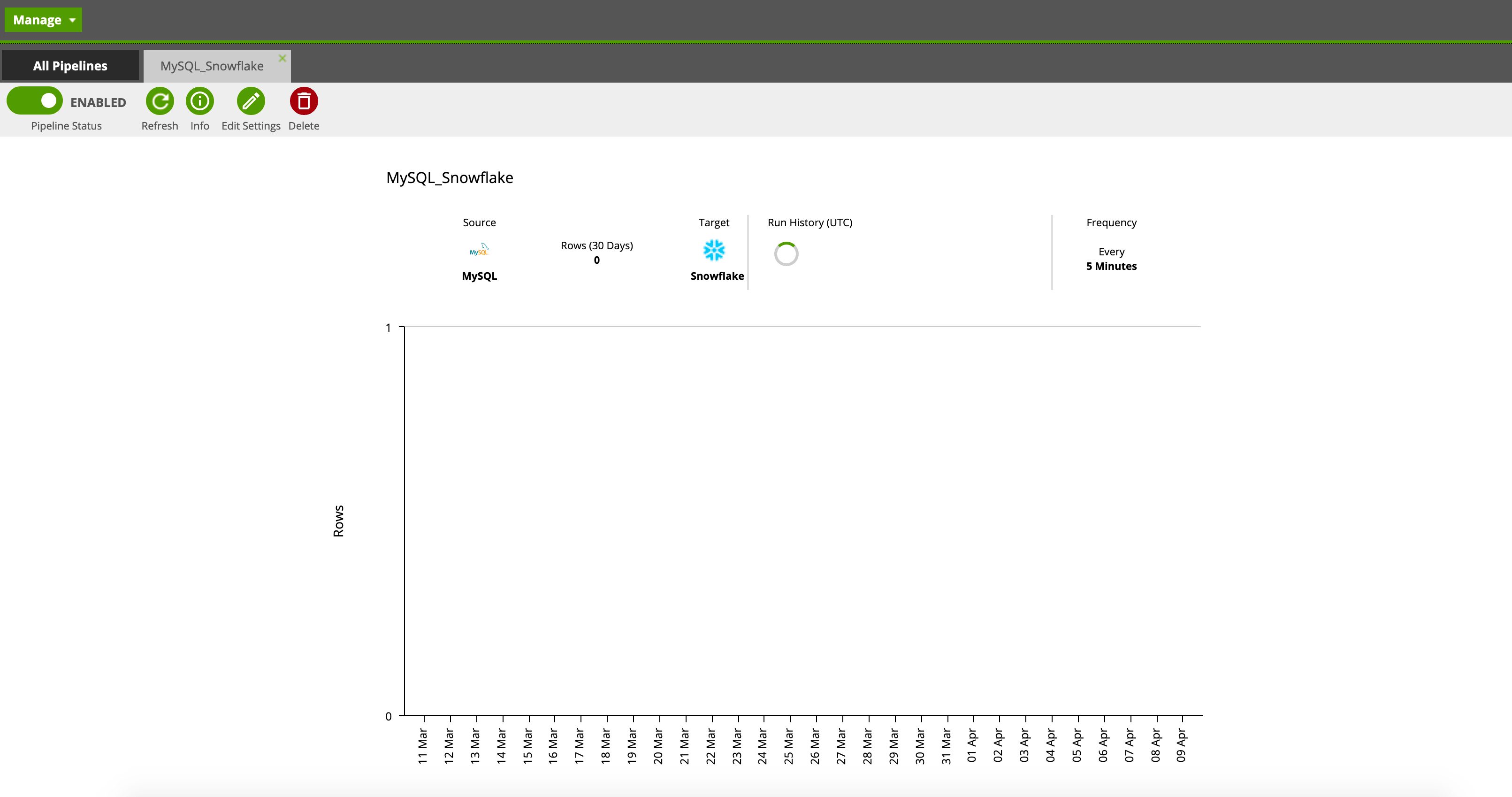
Now that we’ve built our pipeline, we can leverage the power of our Snowflake warehouse to power our company’s dashboards, analysis, and advanced analytics projects—the possibilities are virtually endless. That said, at the foundation, we’ll need a well thought out organizational data strategy before doing so.
Reach out to UDig to explore the multitude of cloud tools that allow organizations to get started moving data quickly with minimal cost or support.
